Quienes somos
Proyecto TLÖN
Actividades
Enlaces



¿Qué es una red Ad hoc? es una red de computadores conectada por interfaces inalámbricas, con un nivel de recursos dinámico, capaces de proveer servicios sin importar las condiciones dinámicas y estocásticas de los nodos al transcurrir el tiempo. Dos propiedades caracterizan a este tipo de sistemas; la primera de ellas es la auto-organización, y la segunda, no menos importante que la anterior la de tener una infraestructura descentralizada. Razón por la cual este tipo de sistemas pueden ser capaces de generar comportamientos pseudosociales desde el instante de su conformación hasta el fin de su operación. Formalmente las redes Ad Hoc son un grafo aleatorio (Newman, 2003) con un conjunto de vértices, comúnmente llamados nodos, en este caso móviles, unidos por un conjunto de enlaces denominados aristas, que cambian de forma dinámica en función del tiempo y las condiciones del ambiente por ejemplo, las peticiones de los usuarios.
Una definición más cercana al ámbito de este proyecto es la siguiente una nube móvil es una plataforma computacional flexible, dinámica y estocástica que gestiona recursos computacionales distribuidos que son enlazados inalámbricamente; estos a su vez, pueden ser cambiados, movidos, aumentados y en general, combinados de formas novedosas. (Fitzek, Katz, 2014).
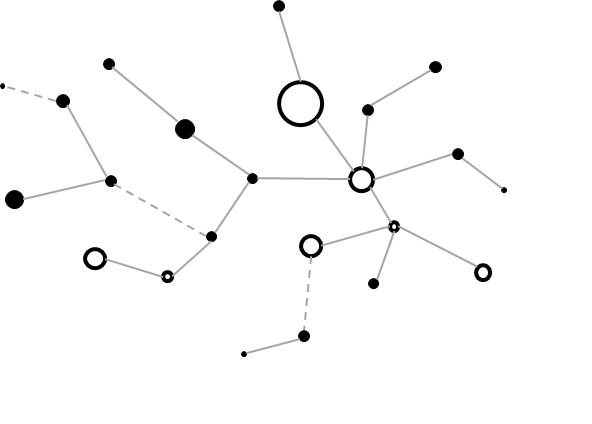
Figura 1. Topología de red Ad hoc.
La virtualización es la creación de un conjunto de arquitecturas lógicas usando un conjunto dado de entidades físicas, pero de una manera transparente para el usuario. (Wang, Prashant , Tipper, 2013). La virtualización de recursos en este contexto busca, crear un servidor de alta disponibilidad sobre la infraestructura de la red Ad hoc, además se deben tener en cuenta las condiciones de los enlaces dinámicos. Las características de movilidad y las necesidades de convergencia han llevado consigo el desarrollo en paralelo de diversas tecnologías orientadas a infraestructura como servicio (SaaI en inglés) o incluso redes como servicio (NaaS en inglés), todo esto enmarcado en sistemas de virtualización, o mejor en esquemas donde el software o una capa lógica superior cobran fuerza para su despliegue como lo son las redes definidas por Software (SDN en inglés ).
Es importante indicar que estos proyectos de virtualización inalámbrica no están bajo las condiciones de las redes Ad Hoc, las cuales en cierto modo son opuestas a las características mínimas requeridas por la virtualización inalámbrica: coexistencia, flexibilidad, aislamiento, escalabilidad, convergencia, algunas son las mismas como la movilidad y el uso de recursos limitados como lo es el espectro.
La característica de movilidad y las necesidades de convergencia han llevado consigo el desarrollo en paralelo de diversas tecnologías orientadas a infraestructura como servicio (SaaI en inglés) o incluso redes como servicio (NaaS en inglés), todo esto enmarcado en sistemas de virtualización, o mejor en esquemas donde el software o una capa lógica superior cobran fuerza para su despliegue como lo son las redes definidas por Software (SDN en inglés ).
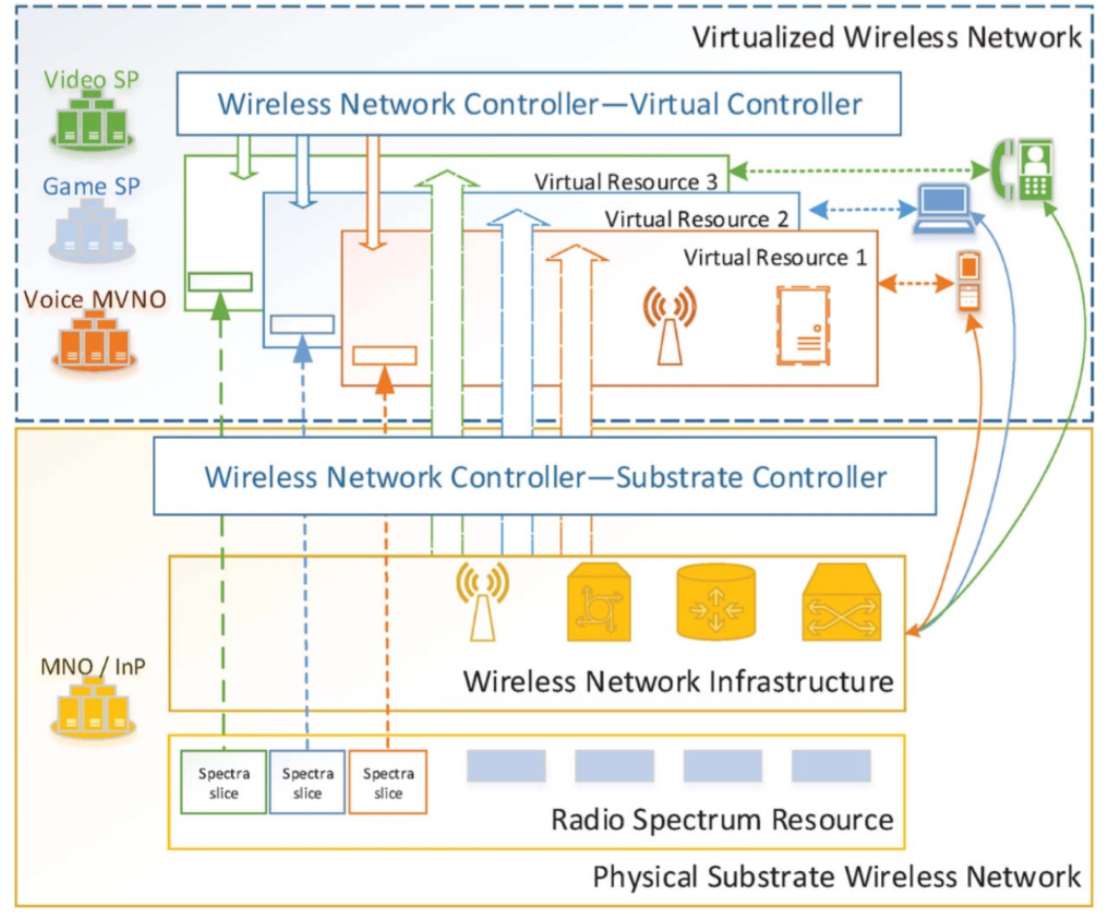
Figura 2. Esquema de virtualización de redes inalámbricas.
Los sistemas multi-agente son parte de la inteligencia artificial distribuida y han ganado considerable aceptación durante los últimos años debido a su capacidad solucionar problemas complejos. Estos sistemas pueden funcionar de manera descentralizada y permiten incluir propiedades como robustez y adaptación, las cuales son de la gran importancia en ambientes no estacionarios. Debido a la ausencia de control centralizado, los agentes pueden competir, cooperar o simplemente coexistir generando la necesidad de construir mecanismos que permitan solucionar problemas a través de acciones colectivas. Estas características los convierten en un modelo promisorio para operar sobre sistemas como las redes ad hoc.
En la Figura 3 se muestra el esquema de operación del sistema multi-agente. En este caso, la organización y el propósito del sistema debe emerger como consecuencia de las interacciones locales entre sus componentes; el objetivo no debe ser programado o controlado de manera explícita. Los componentes deben interactuar de forma autónoma, adaptando sus comportamientos a las posibilidades que ofrece el contexto de operación.
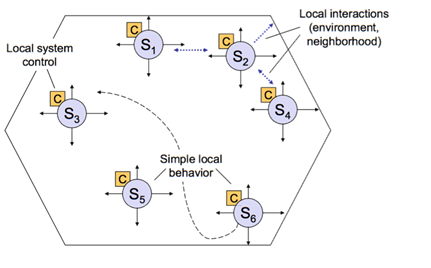
Figura 3. Esquema de operación del sistema multi-agente.
Un lenguaje es un conjunto de elementos que permite expresarnos y comunicarnos con otros entes, ya sean personas, animales, computadores, etc. Este mismo concepto se traduce a los sistemas de cómputo a través de un lenguaje de programación, el cual se compone de tres elementos: parte léxica, sintáctica y semántica. Se puede decir también que los lenguajes de programación son una herramienta que se utiliza para solucionar un problema en particular, como se muestra en (Aho, 2007) y (Terfloth, 2008). Para la implementación del lenguaje de programación es necesario la realización de un compilador.
En la Figura 4 se encuentra la descripción de la composición de un compilador para un lenguaje de programación. Al realizar la división por capas etapas, se han definido las funciones básicas que debe realizar un lenguaje de programación. Empezando con la entrada que son las instrucciones del usuario o programa fuente, luego pasa a un analizador léxico, que se encarga de hacer la división de las instrucciones en tokens que serán la entrada para en analizador sintáctico. El analizador sintáctico tiene como propósito revisar la sintaxis de las instrucciones del programa fuente en donde se verifica si tiene una estructura bien definida. La tercera capa es el analizador semántico, en este módulo se analiza si las instrucciones tienen significado de tal forma que se pueda proceder con las funciones u operaciones indicadas en el programa fuente. Los tres últimos módulos se encargan de realizar el proceso de generación y optimización de código para que la máquina ejecute las instrucciones dadas
Estos principios son mantenidos en los lenguajes de dominio específico, pero guardan las proporciones dependiendo de la aplicación para la cual han sido diseñados.
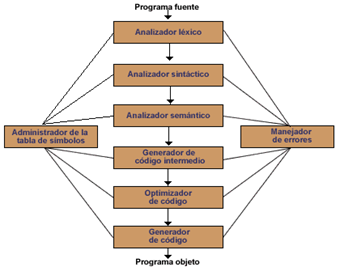
Figura 4. Composición de un compilador para un lenguaje de programación.
Network Coding es un paradigma de transmisión propuesto por Ahlswede et al.1 en el año 2000. Es reconocido como un avance importante sobre el modelo de transmisión de información propuesto por Claude Shannon en el año 1948. Desde la aparición del artículo seminal donde se propuso Network Coding, muchos investigadores han realizado un esfuerzo considerable para estudiar la teoría y las aplicaciones de este modelo de transmisión.
La diferencia más importante entre Network Coding y los paradigmas de transmisión tradicionales es que los nodos al interior de la red pueden aplicar procedimientos de codificación sobre los paquetes, una actividad que va más allá del store-and-forward simple.

Figura 5. Funcionamiento básico de Network Coding en un dispositivo de red.
Los beneficios de Network Coding incluyen un mejoramiento en el rendimiento (throughput) de la red, reducción en el consumo de energía, reducción en el costo del ancho de banda, entre otros. Debido a estos beneficios Network Coding tiene aplicaciones en diversos tipos de redes: redes ad hoc inalámbricas, redes de distribución de contenido, redes de almacenamiento distribuido, distribución segura de llaves criptográficas, tomografía de la red de datos, etcétera.
Network Coding también introduce nuevos retos y oportunidades en seguridad y privacidad. Un problema es que la transmisión de datos aumenta su vulnerabilidad a los ataques de polución: un único paquete malicioso puede contaminar un grupo de paquetes buenos durante el proceso de codificación intermedia y arruinar la integridad de los datos. Por otro lado, podemos aprovechar las propiedades de secrecía intrínsecas de Network Coding como un mecanismo de seguridad para proporcionar servicios de confidencialidad.